tl;dr TF-IDF

Words that are highly specific and therefore descriptive of the larger context tend to be longer and less frequently occurring. Alternatively, words that appear with significant frequency in a body of text surely bear some relevance to the article's topic.
Following from this reasoning I've added a "hashtagSuggestions" method to my Authtools repo. It can be tuned to the text by altering the desired percentile to use. For frequently occurring text it finds words occurring in the upper percentile of the distribution. For high information words, it finds words in the lower percentile. The problem is that each text is different. Size difference alone contributes to variability. A haiku may not even have a large enough sample size to fit any distribution to.
Enter tf-idf. tf denotes Term Frequency, the frequency of a word the text. It's higher for our frequently occurring words.

idf reduces this score for words that are naturally frequently occurring within a collection of documents. For example, if we were classifying an article from Guns and Ammo magazine the appearance of "gun" wouldn't be particularly meaningful to the article and should therefore be penalized in the score.
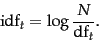
*N = Number of documents in the Corpus
df = The number of documents containing term t
log here is base 10
Per word we multiply them as follows, like the product of two independent probabilities to produce a blended score, the higher the more descriptive. The words with the highest tf-idf in the document should be the most informative as to its general content.
tf-idf = tf x idf
Overall, tf-idf behaves like the use of percentiles, returning almost same result. However it alleviates the need for per-document percentile fitting and performs a cross document check. Pairing the entropy-syllable descriptive measure I created with tf-idf gives a more well rounded description of the text. Tf-idf gives words that occur with uncommon frequency. Syllable-Entropy gives infrequent but highly technical words, likely to be specific to the context at hand.
For more fun, check out these word cloud graphics formed based on tf-idf.


Comments
Post a Comment